Menu
.png)
.png)

By Brett Mershman, Sr. Director, Data Science
What are the two most frequently used letters in technology these days? If you guessed AI, you might be onto something. Reuters recently found that ChatGPT, the popular AI chatbot, had over 180 million users in August 2023. While we observe millions of people exploring the possibilities of AI-generated content, companies also have the opportunity to use AI and machine learning to improve processes and business outcomes. At NCS, we did just this for our campaign measurement solution.
NCSolutions started using machine learning, a subset of AI, over 10 years ago to enhance our methodologies for the campaign measurement services we provide to CPG brands. Not only did this allow us to scale our measurement, but it also improved our speed to market, helped us be more agile and provided more precision in the measurement results we deliver. Ultimately, using machine learning methodologies supports our mission of improving the effectiveness of advertising for all media.
Recently, we had the opportunity to present our latest research; we compared the efficacy of machine learning against traditional campaign sales lift measurement techniques at the ARF AUDIENCExSCIENCE conference in March.
For those seeking the cliff notes version (we know you’re busy), the results are in: Machine learning came out on top for campaign measurement. If you have a little time, read on to learn how machine learning and traditional campaign measurement techniques fared in our deep dive.
We looked at three traditional techniques and compared them to our machine learning methodology.
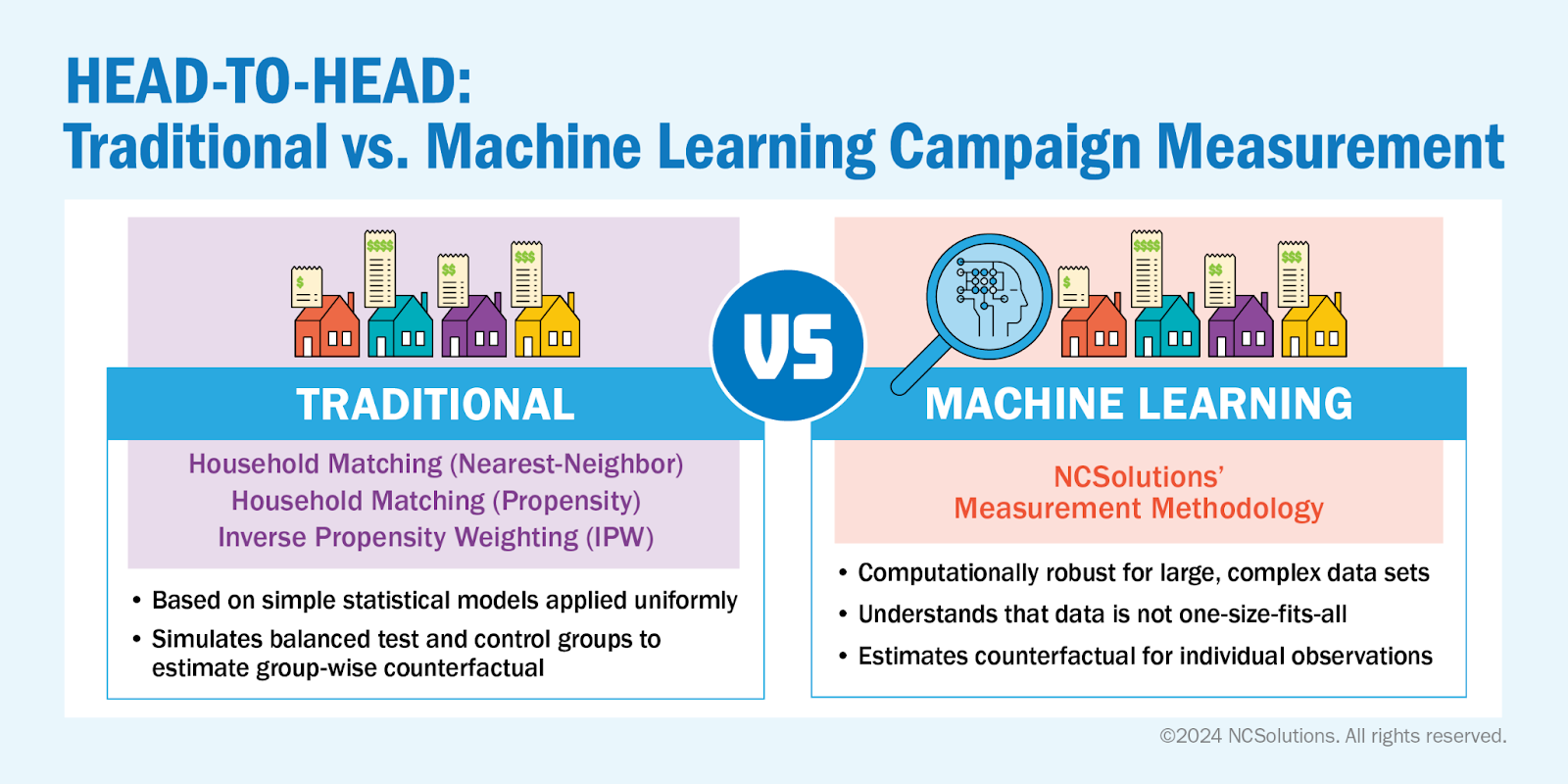
The traditional methods we looked at used simple statistical models that were applied uniformly. These methods then simulate test and control groups to estimate what happened to households exposed to an ad and households not exposed to an ad.
Conversely, the machine learning method is robust to work with complex data sets and understands that data is not one-size-fits-all. Instead of looking at test and control, this method uses different models to estimate the true effect (a counterfactual) for what would have happened to the same group of households.

DEFINING THE EXPERIMENTS
The Data: Each of the 11 experiments we ran spanned several CPG departments, and we compiled household-level purchase data along with demographic information over a one-year period. We already knew which households were exposed to advertising from existing campaign data, so we used machine learning to ask what would happen if those households weren’t exposed to an ad.
The True Effect: In the real world, we will never know the true effect with 100% certainty, so we use simulations to estimate the true effect with a set of defined outcomes. This gives us the expected outcome of advertising within each experiment, or what we call the true effect.
The Measures: We specifically looked at accuracy, validity and power to gauge how each experiment measured up to our pre-defined true effect.
- Accuracy: measures how closely our simulations matched the true effect
- Validity: the percentage of times our predictions are close to the actual outcome
- Power: how wide the confidence interval is
THE RESULTS
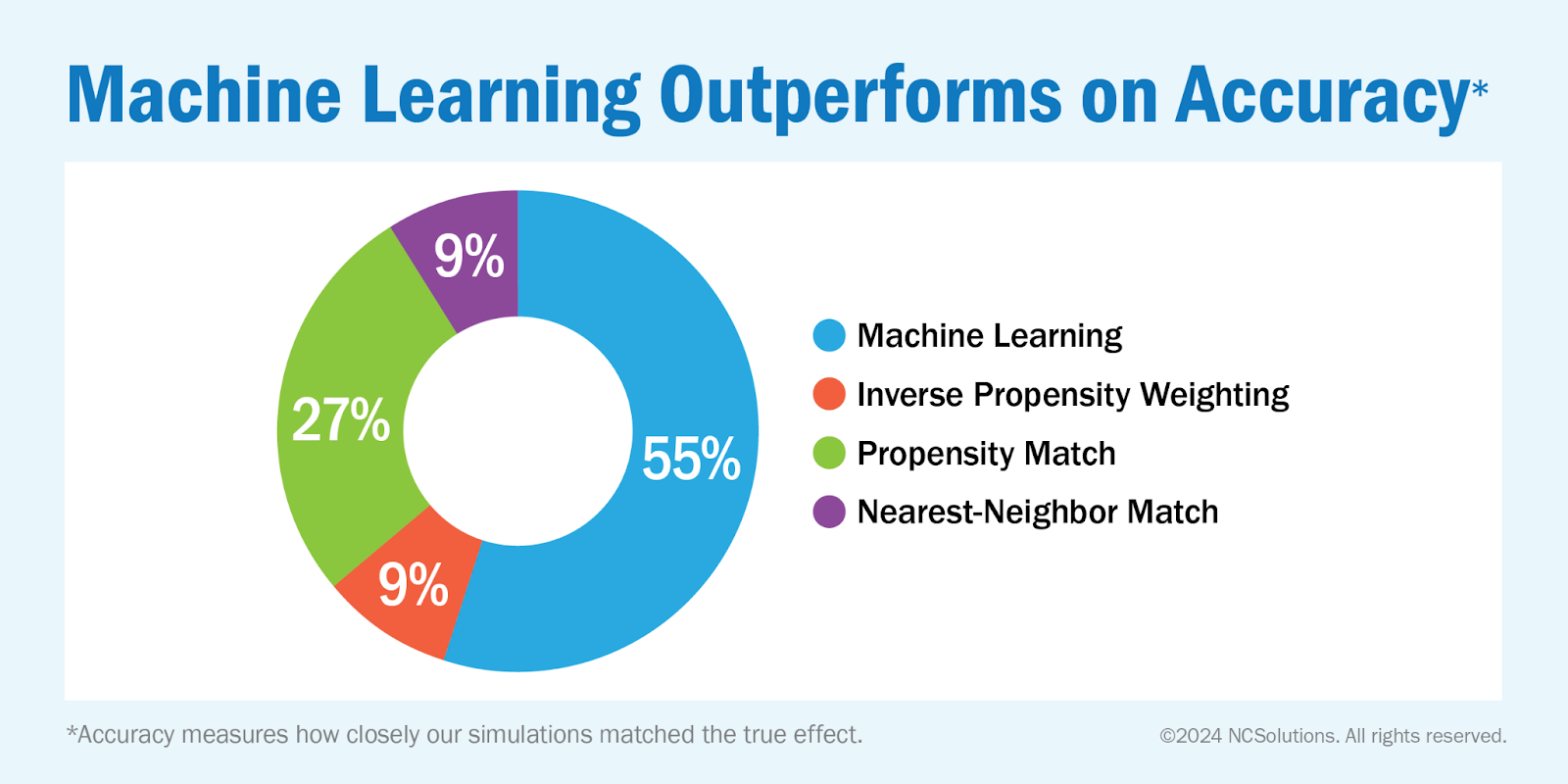
Accuracy measures how closely our simulations matched the true effect. It's like hitting the bullseye on a target: the closer the experiments are to the true result, the more accurate the experiment is. For our test, machine learning achieved the closest approximation 55% of the time or six times out of the 11 experiments. The next closest method was propensity matching, which only achieved the closest match in three of the eleven experiments.
Validity is the percentage of times our experiments are close to the true effect. It’s like a basketball player’s shooting accuracy. If their shots are valid 8 out of 10 times, it means they’re making the basket 80% of the time. Just like a skilled player consistently makes successful shots, a valid experiment is reliable and consistently close to the true effect.
For these experiments, validity was consistent across each method. However, machine learning provided valid estimates most often (10 of 11 times) compared to the other methodologies.

Power is how wide the confidence interval is – the wider it is, the less confidence you have. Think of it like a camera lens. When the lens is sharply focused on a smaller area, the image is clear, and you have confidence in what’s in your picture. When the focus is widened, the image becomes more blurry and you’re not as certain about the picture. Confidence is power.
In these experiments, we found machine learning had the lowest average width, followed closely by inverse propensity weighting. While these are all close, machine learning proved more powerful than the other methods.

ACCOUNTING FOR ALL THE RIGHT VARIABLES
When you’re looking for campaign measurement, you want to be certain that the data your measurement provider is using is comprehensive and robust and accounts for all of the right variables. Machine learning relies heavily on the quality and completeness of the input data to produce meaningful insights.
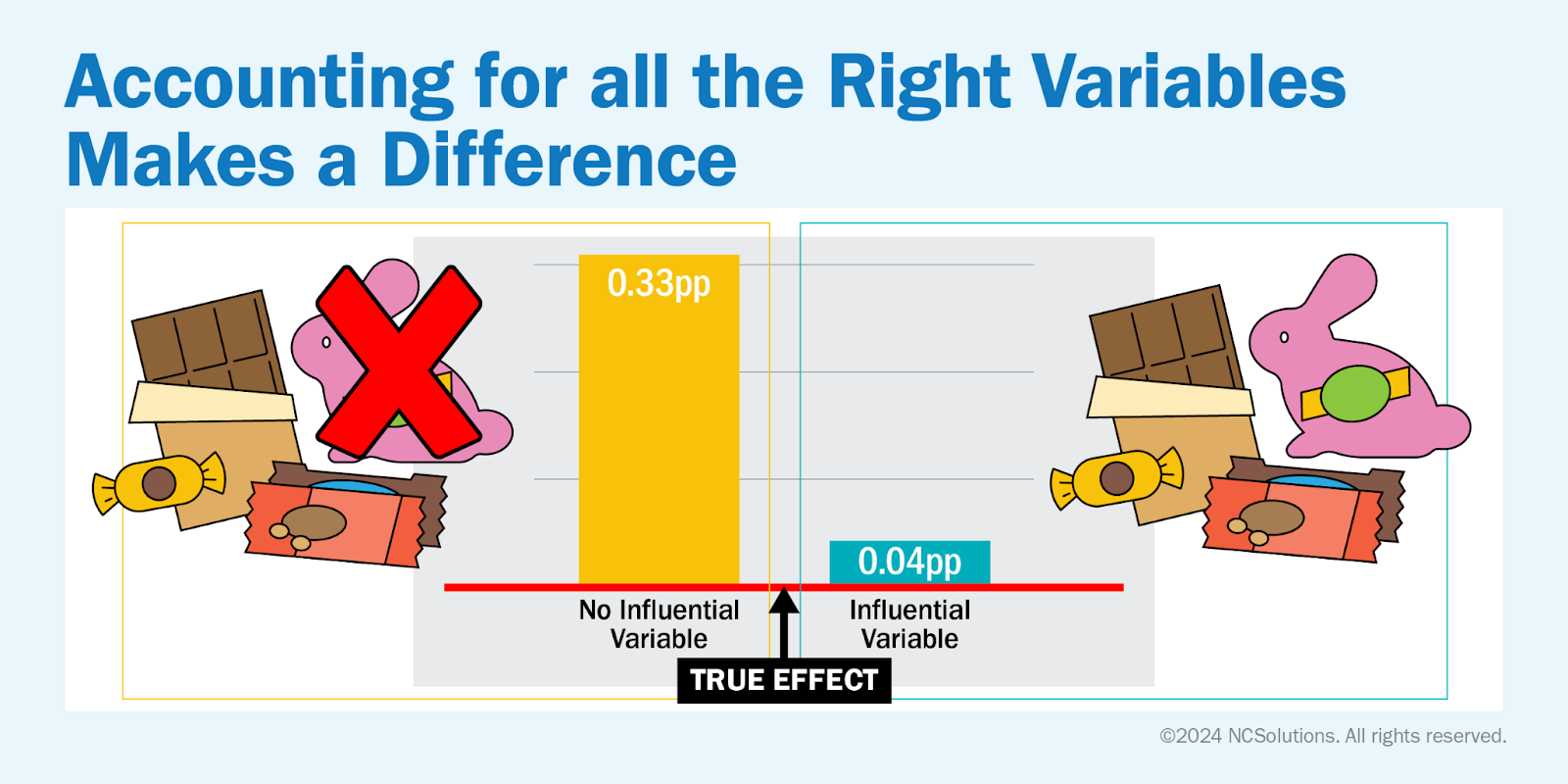
To demonstrate this point, in one of our experiments, we trained a machine-learning model twice. The first time, we used all available covariates; the second time, we left out a highly influential variable in the outcome. Translation – we left out some key data critical to the right answer to the question we were asking.
As illustrated below, there are some types of candy that are only available around Easter (yes, chocolate bunnies are one of my favorite examples). If a household typically buys chocolate bunnies only during the Easter shopping season and doesn't purchase the same brand of chocolate in the non-bunny variation (a chocolate bar, for example) that is sold all year long, that household’s propensity for buying the chocolate bunnies is quite high. You could only predict this if you included the household’s shopping behavior from last Easter – this is the right data to include in the model for a seasonal view of chocolate purchasing or a holistic view of buying that includes seasonal varieties.
When purchases from last Easter (the influential variable) were left out of the model, the distance from the true effect increased from .04 to .33 percentage points. By leaving out an important, influential variable, the measurement is further away from the true effect–in other words, it’s providing significantly less accurate results.
This example really underscores the principle that campaign measurement is inherently data-dependent – a concept well-captured by the adage 'garbage in, garbage out.' Ask your campaign measurement provider if they’re accounting for the data variables, which is one of the ways you can ensure that you have the right data for accurate, valid and powerful results.
Machine learning is so much more than a buzzword; it's a reliable ally in assessing the effectiveness of your advertising efforts. For NCS, machine learning is a crucial component of how we look at future innovations. This experiment demonstrated that machine learning's precise predictions and consistent results are ideal for measuring incremental sales lift and return on ad spend in the CPG advertising industry. Also, it provides agility that ensures optimal performance across various campaign sizes, giving brands of varying sizes and campaign budgets access to advanced analytics.
What we know to be true at NCS is not only based on this experiment but also on the 14 years of history we have with CPG brands measuring advertising performance.
When evaluating measurement providers, prioritize data robustness, sample size, methodological accuracy and actionable insights.
These critical elements ensure optimized advertising strategies based on trustworthy data analytics and are essential to any sales lift measurement.
Are you looking to see machine learning at work? Check out how Roku used NCS’s machine learning measurement to understand how a personal care brand campaign performed.

Subscribe for Updates
GET INSIDE THE MINDS OF CPG BRAND MARKETERS
Learn about their data-fueled strategies
SNAG YOUR COPY OF THE REPORT TODAY
WONDERING HOW CONSUMERS RESPOND TO INFLUENCER MARKETING?
See how creating content drives results
DOWNLOAD YOUR COPY NOW
WANT TO KNOW MORE ABOUT HEALTH AND ECO-MINDED SHOPPERS?
Get CPG insights to engage your buyers
ACCESS THE E-BOOK TODAY